Distributed System VII
这一篇介绍Popular Systems, 包括最近比较火的MapReduce/Hadoop,Spark和Distributed Machine Learning. 不是重点,随便写写的一个。
Data Intensive Computing & MapReduce
讲High-performance computing(HPC), Cluster computing和MapReduce.
HPC
| HPC Machine | Programming Model | HPC Operation | Fault Tolerance |
|---|---|---|---|
 |
 |
 |
 |
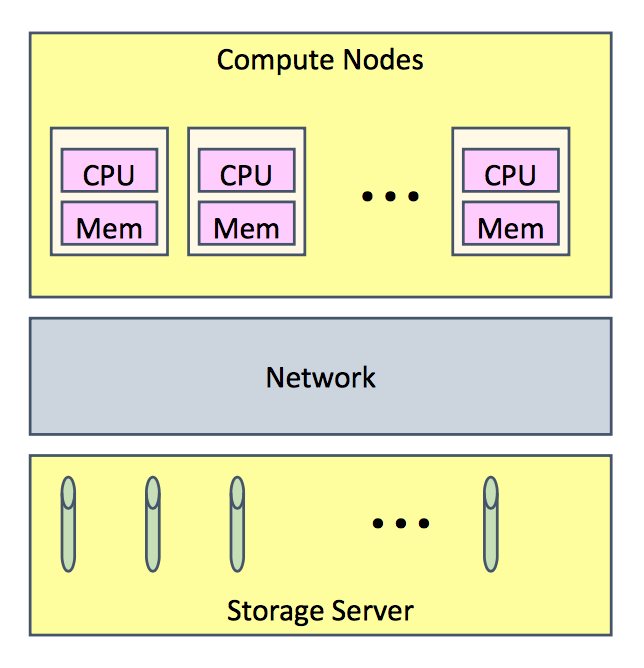
- Machine: computer nodes, networks, storage servers
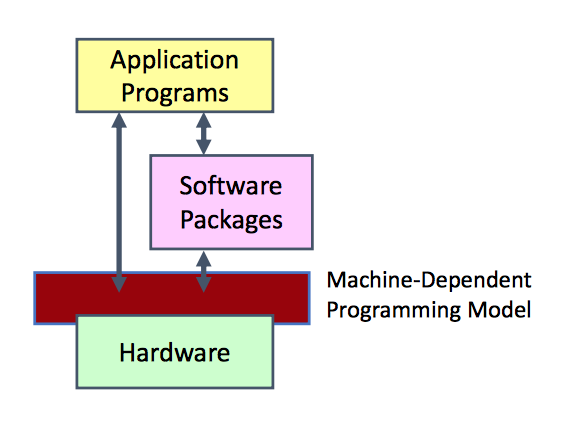
- Programming model: programs described at low level, rely on small number of software packages
- Operation: long-livedprocesses, make use of spatial locality, hold all program data in memory, high bandwidth communication
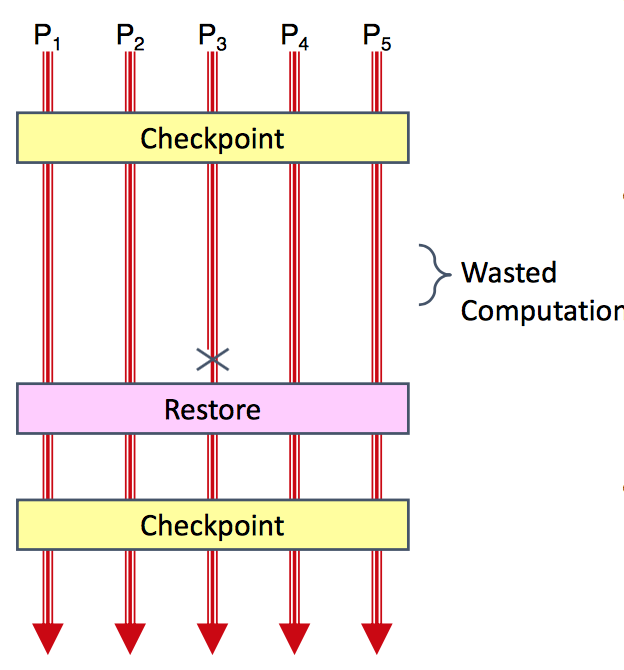
- Fault Tolerance: checkpoint, restore, rerformance scaling
MapReduce
MapReduce, 我不喜欢的一个技术。对大数据通过Map, Shuffle, Reduce进行处理。Map过程输出<key, value>键值对到Reduce过程,Reduce过程对key相同的键值对归并到一台机器处理。Map过程全部结束后Reduce过程才会开始,每个过程的时间由最慢的机器决定,所有的数据以及中间结果全部存在硬盘中。
MapReduce API
- Requirements
- Programmer must supply Mapper & Reducer classes
- Mapper
- Steps through file one line at a time
- Code generates sequence of <key, value> pairs
- Default types for keys & values are strings
- Reducer
- Given key + iterator that generates sequence of values
- Generate one or more <key, value> pairs
Implementation
- Built on Top of Parallel File System
- Google: GFS, Hadoop: HDFS
- Provides global naming
- Breaks work into tasks
- Master schedules tasks on workers dynamically
- Typically #tasks » #processors
- Net Effect
- Input: Set of files in reliable file system
- Output: Set of files in reliable file system
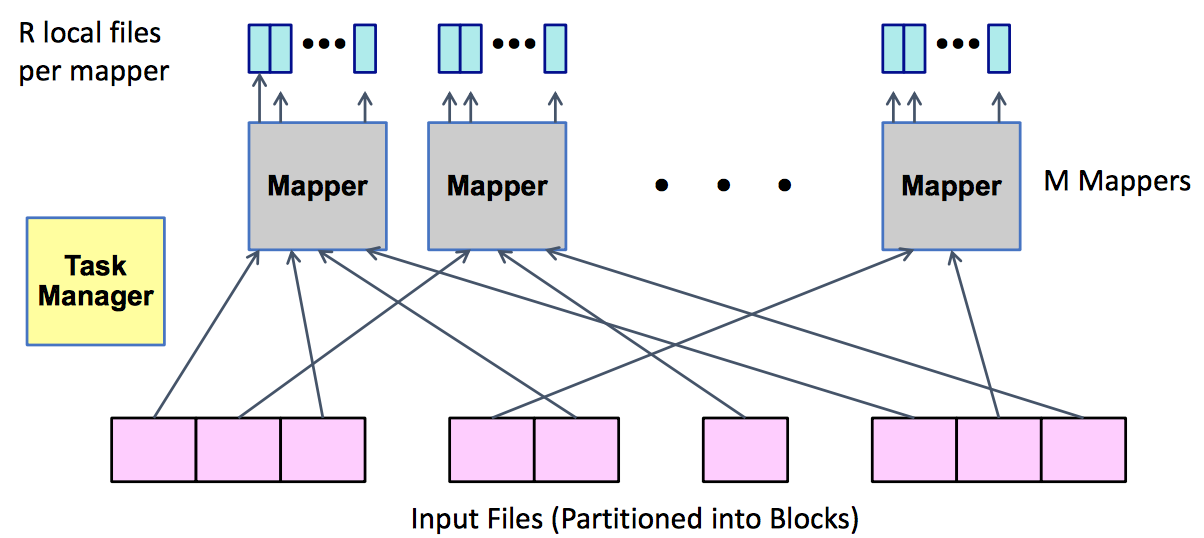
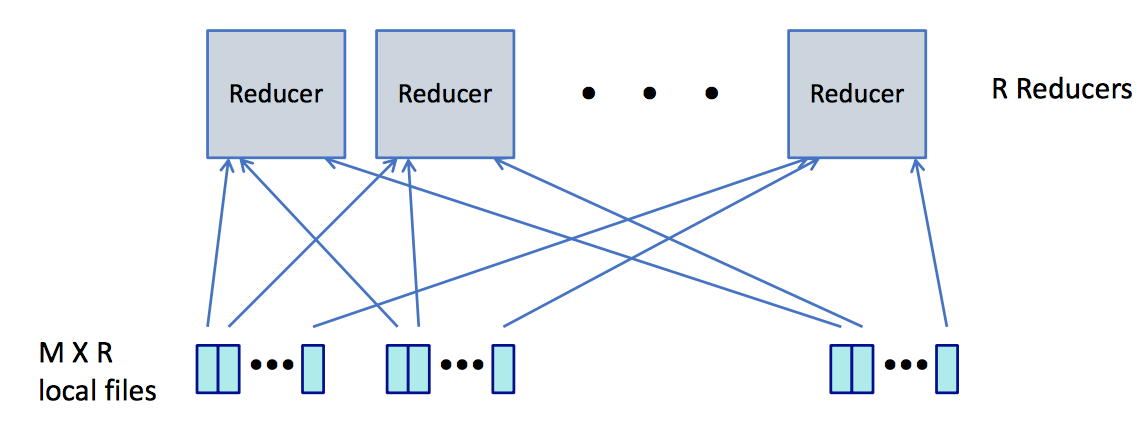
Operations
| Mappingg | Shuffling | Reducing |
|---|---|---|
 |
 |
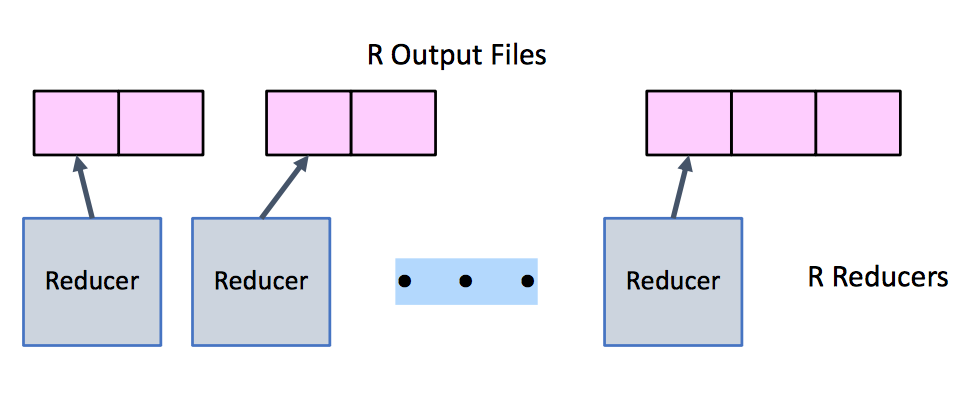 |
| Dnamically map input file blocks onto mappers, each generates key/value pairs from blocks, each writes R files on local file system | Each Reducer handles 1/R possible key values, fetches file from M mappers, sorts all entries to group values by keys | Each Reducer executes reducer function for each key, writes output values to parallel file system |
- Characters
- Computation broken into many,short-lived tasks
- Use disk storage to hold intermediate results
- Strengths
- Great flexibility in placement,scheduling, and load balancing
- Can access large data sets
- Weaknesses
- Higher overhead
- Lower raw performance
- Fault Tolerance: data integrity/recovering from failure
- Assume reliable file system
- Detect failed worker: heartbeat mechanism
- Reschedule failed task
- Stragglers (Tasks that take long time to execute)
- Might be bug, flaky hardware, or poor partitioning
-
When done with most tasks, reschedule any remaining executing tasks
Spark and Distributed ML
Spark介绍,和MapReduce对比。主要介绍SparkRDD,运用in memory的计算和数据共享的方式,因此比起MapReduce在速度上有很大的优势。具体的是将计算分解成为一系列计算,如果在某一步发生了错误可以根据之前的计算和结果恢复。 RDD数据是只读的,也就是说不可更改。因为数据全部存在内存,在进行iteration的计算时有很大的优势。
RDD and Lineage
RDD: Resilient Distributed Datasets
- Provide interface based on coarse-grained operations
- Efficient fault recovery using lineage
- Each operation is applied to many elements
- Low each operation
- Recompute lost partitions on failure
Operations
- Transformations: create new RDD from existing one
- Actions: return value to caller
- Persist RDD to memory
Consistency & Fault Recovery
- Immutable datasets: recreate/checkpoints
- High overhead: copying data (no mutate-in-place)
- Needs lots of memory (might not be able to run your workload)
MapReduce Vs Spark
| MapReduce | Spark RDD | |
|---|---|---|
| Framework | 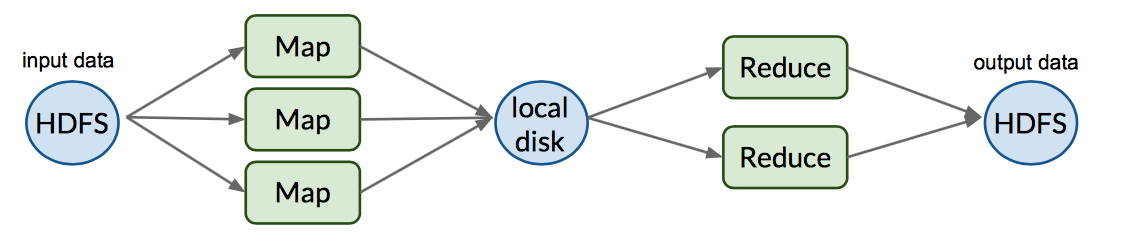 |
 |
| Typical Applications | Sequence steps, each requires map/reduce; Series of data transformations; Iterating until convergence | Streaming analytics, Iterative ML algorithms, Graph/social data |
| Strengths | Simple for users; very general; good for large-scale data analysis; highly expressive and scalable | Overcome disk I/O bottleneck, fast in memory operations |
| Limitations | No locality of data; each map/reduce must complete befor next; Huge I/O to disks and over network | Storage for web applications; incremental web crawlers; data can’t fit in memory |
Distributed ML
介绍了分布式机器学习方面的一些困境,总觉得最后结论是ML不适合分布式来着…失忆∠( ᐛ 」∠)_
Trade-off: stale state & throughput
- Distributed variants highly complex and not always faster!
- Challenges: communication overhead and stragglers
-
Key ideas: P2P+selective communication, bounded-delay BSP
参考资料:
