Parallel Architecture & Programing 叁
不知道自己在干嘛,大概是出现了错觉。 _(:з」∠)_ 日常错觉
不管错觉的事,这篇复习一下performance optimization.
Balancing workload
Ideally: all processors are computing all the time during program execution
Key goals
- balance workload onto available execution resources
- reduce communication (avoid stalls)
- reduce extra work (overhead)
Static assignment
- assignment of work to threads is pre-determined
- two approaches: blocked and interleaved
- simple and zero runtime overhead
- when cost/amount of work is predictable
- “semi-static” assignment - periodically profiles and re-adjusts
Dynamic assignment
- determines assignment dynamically at runtime - not pre-determined
- workload balance and overhead (sync cost) trade-off
- smarter scheduling - long tasks first
- stealing - increase locality
- child stealing, continuation stealing
- gready join scheduling policy
Fork-join parallelism
Natural way to express independent work in divide-and-conquer algorithms(不认识分治法的我orz
日常失忆的我并不记得讲了这个fork-join的并行模式大概看起来是这样的我真的会过吗
Fork: create new logical thread of control
- 父线程调用,创造新的并发子线程
- 子线程和父线程分别异步执行
Join: returns when current function calls have completed
- 子线程结束时调用
- 父线程等待子线程结束
发现这个别家的课件详细介绍了fork-join model
Minimizing communication costs
(三个月后
我也想回家过年呀~ 今天把买了2个月的手办拆开摆上了真的好好看啊。不过手办买多了也没用,等预购的迹部景吾到了可能也不会再买了。(真香预警?
Message passing solver
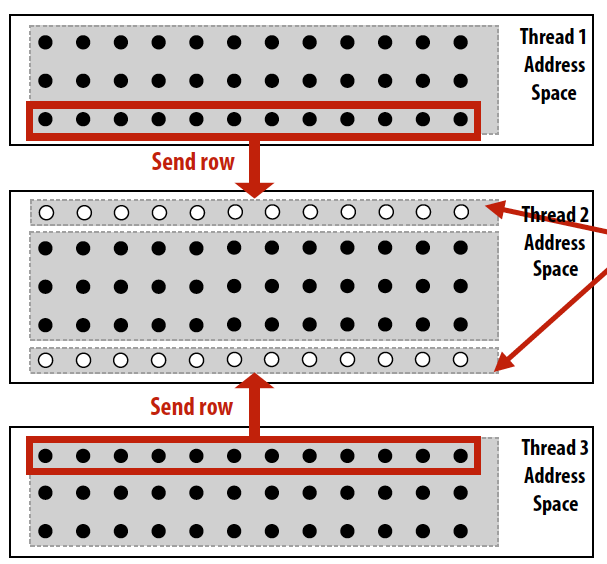
Message passing model的一个例子,data被分成几个部分,每一个部分在一个线程的地址空间中,每个thread完成本地计算后要和相邻thread进行数据交换。
Synchronous (blocking) send & receive
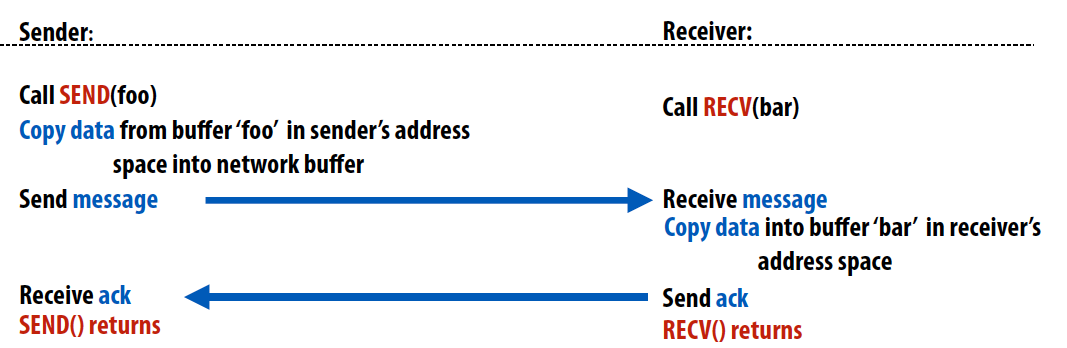
阻塞型通信函数,send()在sender收到receiver发送的ack时返回。recv()在data被复制到receiver的地址空间时返回并且向sender发送ack。这是最容易实现的方式,因此被广泛应用。但是为了避免死锁,必须实现在发送和接受端都有很大buffer空间的情况。这里send()函数需要等待匹配的recv()函数发送ack,因此sender可能会出现aherad messages或者持续发送导致buffer overflow等情况造成死锁。一个解决方法是利用模2操作来确定send()和recv()的顺序,比如下面这段代码就可以避免死锁。
void solve() {
bool done = false;
while (!done) {
float my_diff = 0.0f;
if (tid % 2 == 0) {
sendDown(); recvDown();
sendUp(); recvUp();
} else {
recvUp(); sendUp();
recvDown(); sendDown();
}
…
}
}
Non-blockling asynchronous send/recv
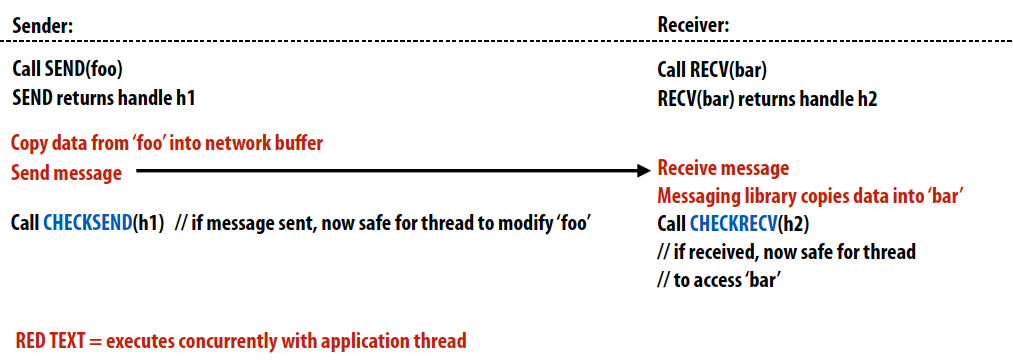
非阻塞型通信函数,send()和recv()均立即返回,并且发送端和接收端在等待消息发送/接受时都可以进行其他工作,利用checksend()和checkrecv()函数来判断消息是否传递成功,即是否可以更改buffer内容。
Pipelining 流水线
说到pipeling,就不得不想到我考试前复习算不明白cycles真的头大脑壳痛。。。最后还是成功的打了个B在这个课上,已经是我能做的最好了! 🤦♂️ 一定是因为不明原因的大脑当机!不是因为我笨_(:з」∠)_ 我很努力复习了第二个期中考试和第二个第一个期中考试了!
Goal: maximing throughtput of many loads
先复习一下延迟和带宽:
- Latency 延迟: The amount of time needed for an operation to complete
-
Bandwidth 带宽: The rate at which operations are performed
- Throughput 吞吐量:the rate of successful message delivery over a communication channel (wiki)
一个指令pipeline的例子如下,如图所示的latency为4 cycles/instruction, throughput为1 instruction/cycle:
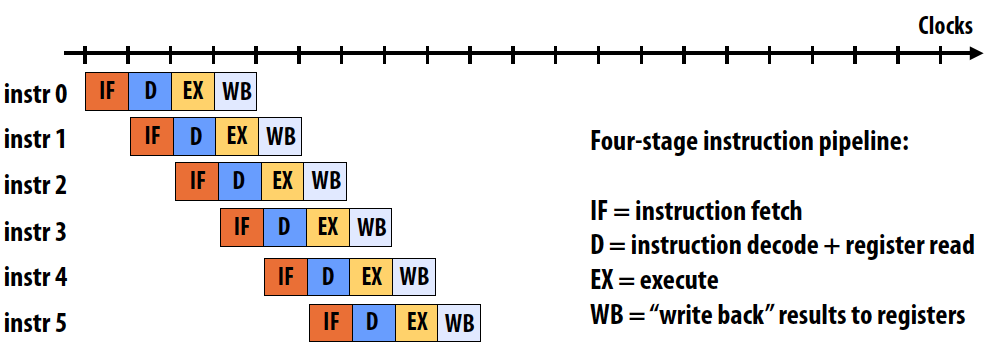
Simple non-pipelined communication:
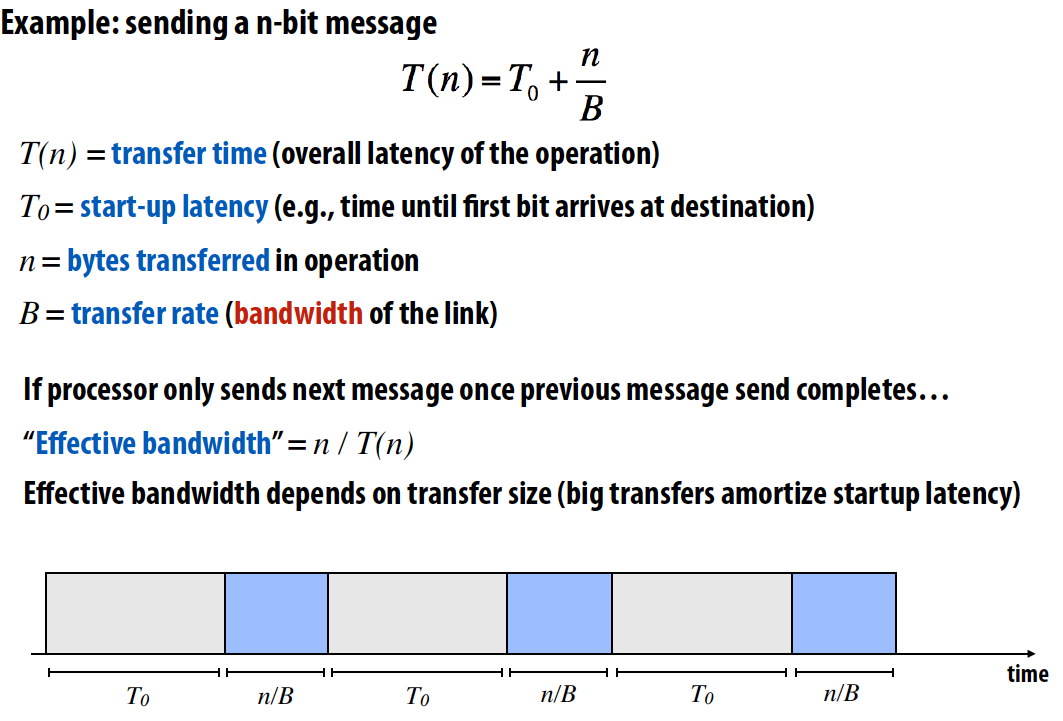
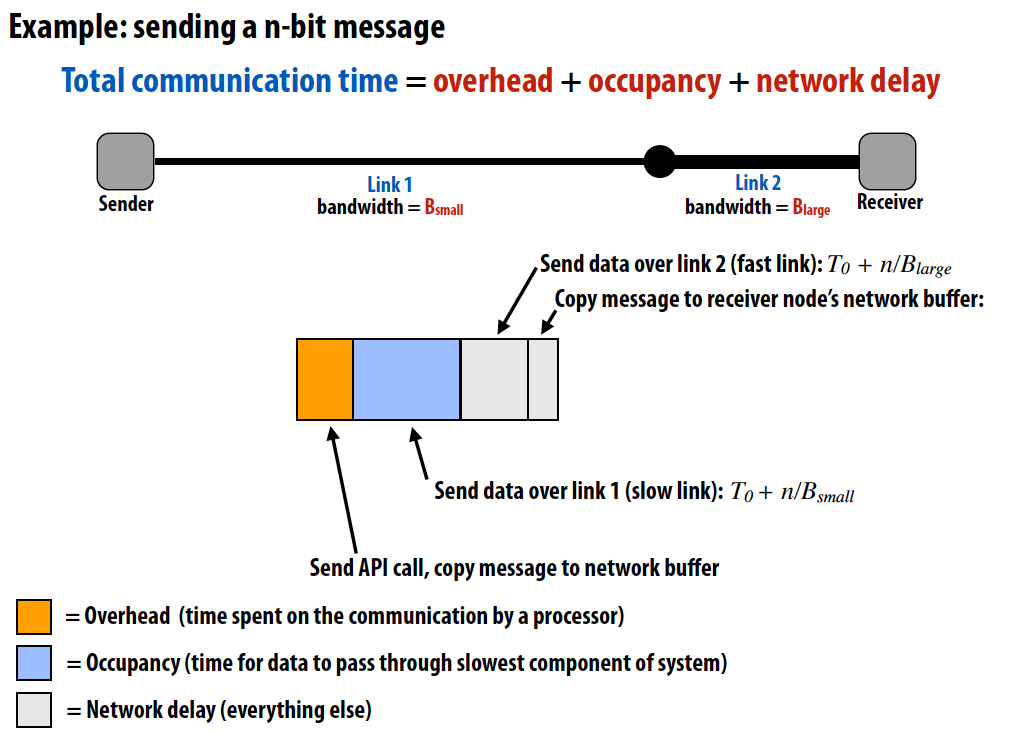
Pipelined communication:
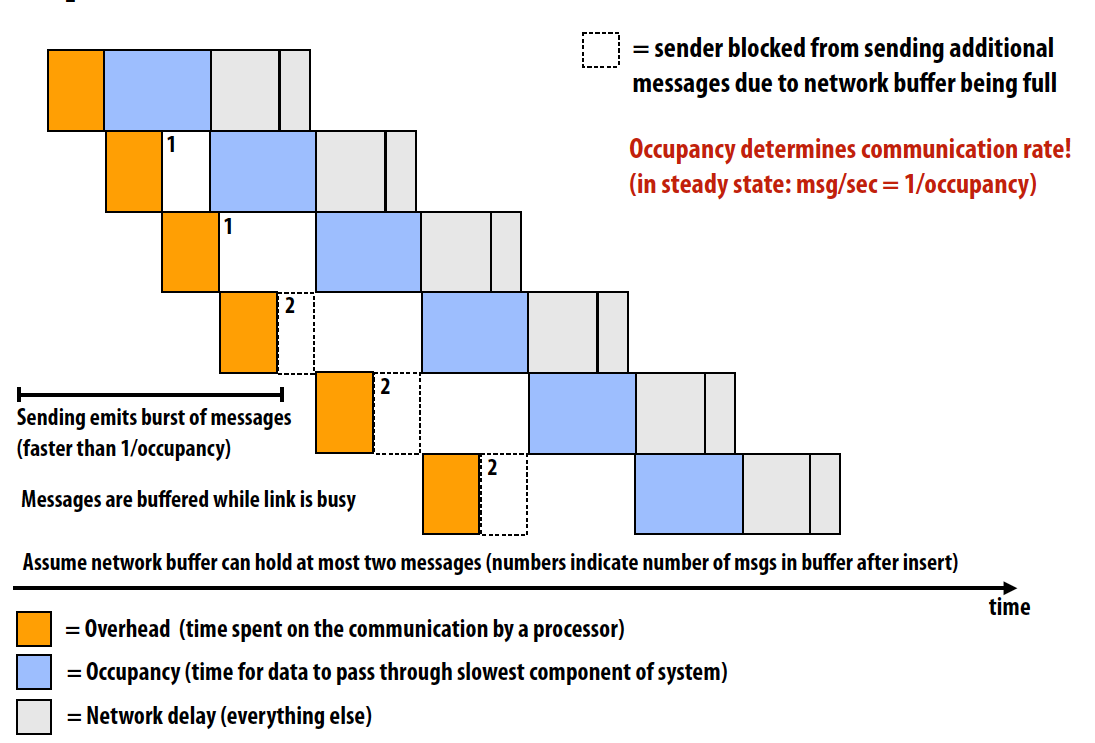
Cost

通信成本 = 通信时间 - 重叠
Two reason for communication
Inherent communication
Communication that must occur in a parallel algorithm, is fundamental given how the problem is decomposed and how work is assigned
Communication to computation ratio 计算通信比
Definition:
Arithmetic intensity 运算强度: 1/communication to computation ratio
High arithmetic intensity (low communication-to-computation ratio) is required to efficiently utilize modern parallel processors since the ratio of compute capability to available bandwidth is high.
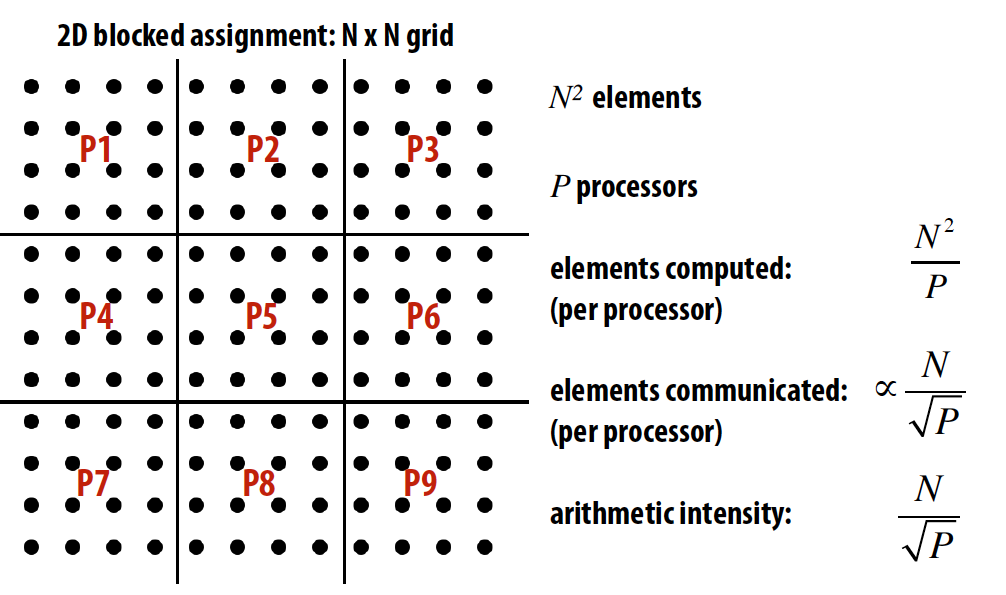
三种不同的任务分配方式对应inherent communication计算:
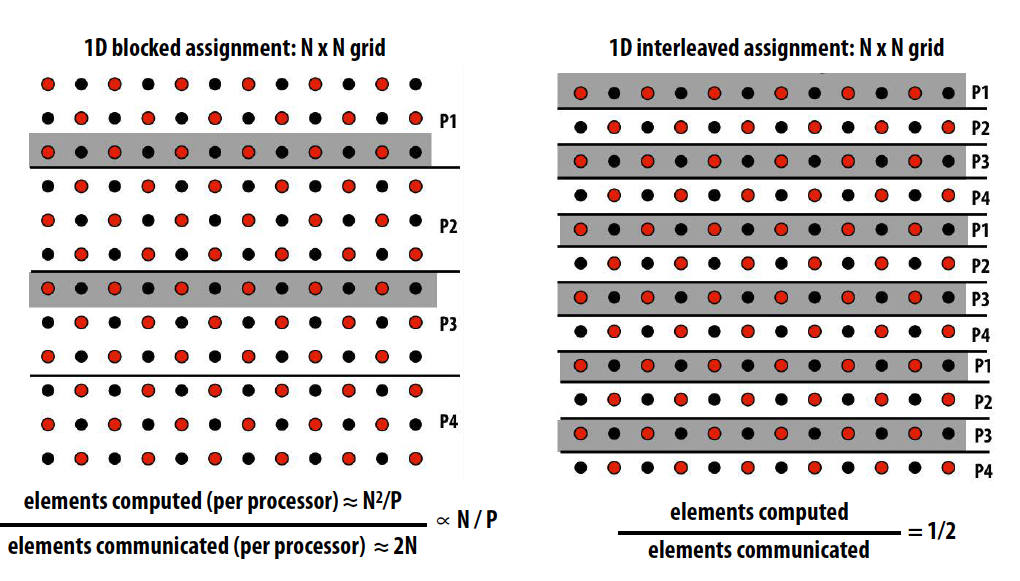
Artifactual communication
All other communication results from practical details of system implementation, depends on machine implementation details
Examples:
- System might have a minimum granularity of transfer
- System might have rules of operation that result in unnecessary communication
- Poor placement of data in distributed memories
- Finite replication capacity
Review of Cs
- Cold miss: First time data touched. Unavoidable in a sequential program
- Capacity miss: Working set is larger than cache. Can be avoided/reduced by increasing cache size
- Conflict miss: Miss induced by cache management policy. Can be avoided/reduced by changing cache associativity, or data access pattern in application
- Communication miss: Due to inherent or artifactual communication in parallel system
不知道这几个的中文是什么,好像分别是冷失效、容量失效、冲突失效和通信失效
Reducing communication costs
- Reduce overhead of communication to sender/receiver
-
Send fewer messages, make messages larger (amortize overhead)
-
Coalesce many small messages into large ones
-
- Reduce delay
-
Application writer: restructure code to exploit locality
-
HW implementor: improve communication architecture
-
-
Reduce contention
-
Replicate contended resources
-
Stagger access to contended resources
-
- Increase communication/computation overlap
- Application writer: use asynchronous communication
- HW implementor: pipelining, multi-threading, pre-fetching, out-of-order exec
- Requires additional concurrency in application
Techniques for reducing communication
用这个grid data access来举例:
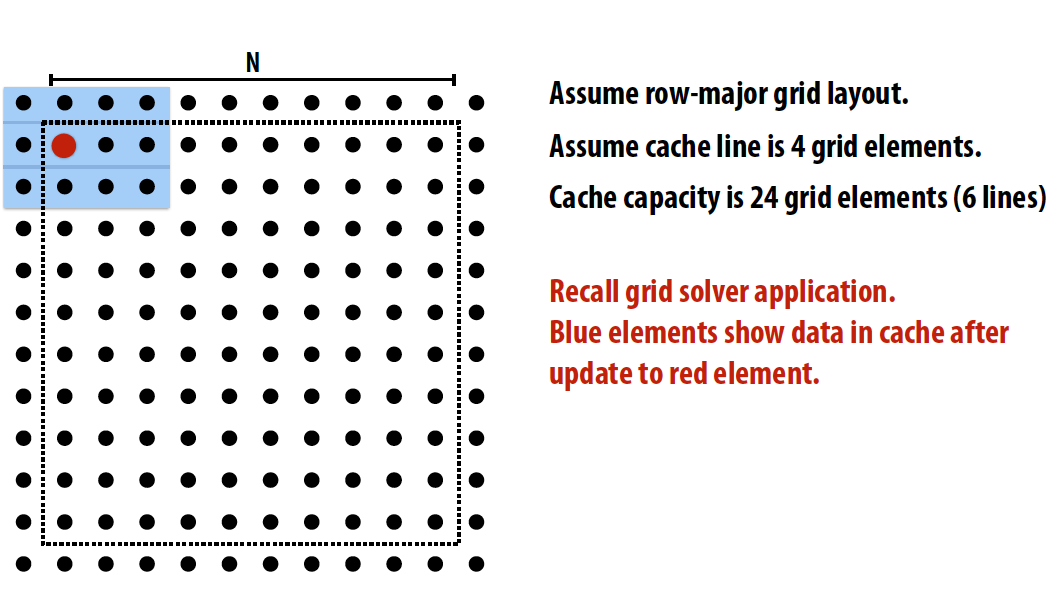
-
Improved temporal locality by changing grid traversal order: “Blocked” iteration order

-
Improced temporal locality by fusing loops

- Improve arithmetic intensity by sharing data
- Exploit sharing: co-locate tasks that operate on the same data
- Reduces inherent communication
- Schedule threads working on the same data structure at the same time on the same processor
- Example: CUDA thread block
- Exploit sharing: co-locate tasks that operate on the same data
-
Reducing artifactual communication: blocked data layout
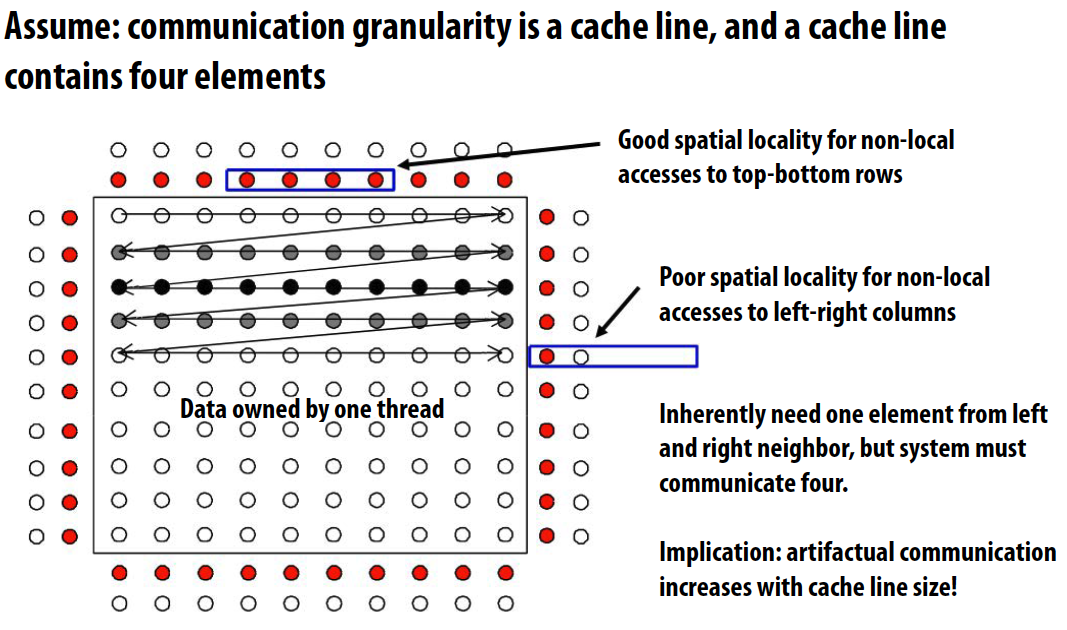
Spatial locality 空间局部性
Granularity 粒度
- Granularity of communication can be important because it may introduce artifactual communication
- Granularity of communication / data transfer
- Granularity of cache coherence

感觉现在看课件也能看懂,当时是怎么了就是看不懂呢?
Contention 竞争
Contention occurs when many requests to a resource are made within a small window of time
举个在并行机器上构建网格式数据结构的例子,比如计算相邻interaction:
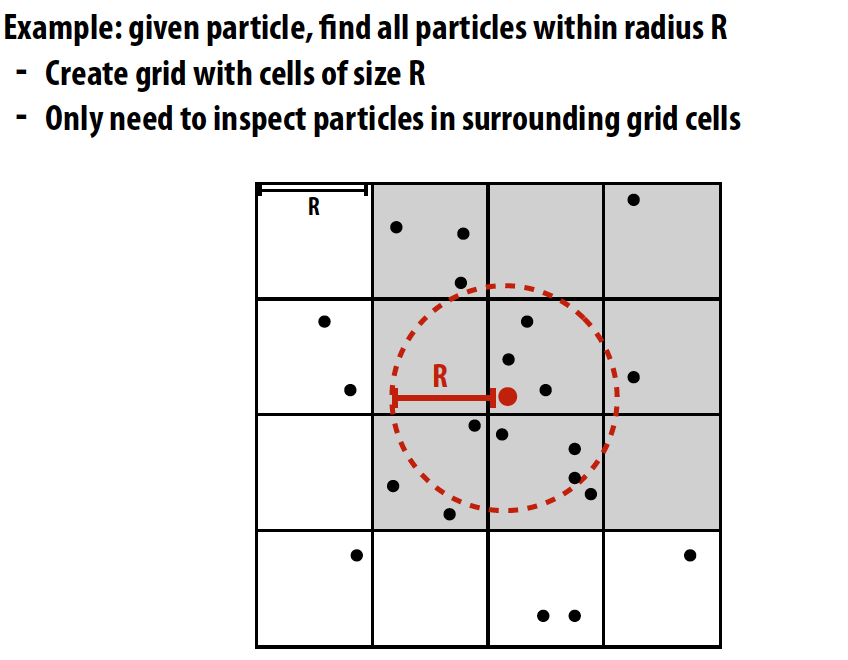
Solution 1: parallelize over cells
- For each cell independently compute particles within it
-
Eliminates contention because no synchronization is required
-
Insufficient parallelism: only 16 parallel tasks, but need thousands of independent tasks to efficiently utilize GPU
- Work inefficient: performs 16 times more particle-in-cell computations than sequential algorithm
list cell_lists[16]; // 2D array of lists
for each cell c // in parallel
for each particle p // sequentially
if (p is within c)
append p to cell_lists[c]
Solution 2: parallelize over particles
- Assign one particle to each CUDA thread. Thread computes cell containing particle, then atomically updates list
- Massive contention: thousands of threads contending for access to update single shared data structure
list cell_list[16]; // 2D array of lists
lock cell_list_lock;
for each particle p // in parallel
c = compute cell containing p
lock(cell_list_lock)
append p to cell_list[c]
unlock(cell_list_lock)
Solution 3: use finer-granularity locks
- Alleviate contention for single global lock by using per-cell locks
- 16x less contention than solution 2, assuming uniform distribution of particles in 2D space
list cell_list[16]; // 2D array of lists
lock cell_list_lock[16];
for each particle p // in parallel
c = compute cell containing p
lock(cell_list_lock[c])
append p to cell_list[c]
unlock(cell_list_lock[c])
Solution 4: compute partial results + merge
- Generate N “partial” grids in parallel, then combine
- Requires extra work: merging the N grids at the end of the computation
- Requires extra memory footprint: Store N grids of lists, rather than 1
Solution 5: data-parallel approach
- Step 1: compute cell containing each particle (parallel over input particles)
- Step 2: sort results by cell (particle index array permuted based on sort)
- Step 3: find start/end of each cell (parallel over particle_index elements)
Improving program performance
-
Identify and exploit locality: communicate less (increase arithmetic intensity)
- Reduce overhead (fewer, large messages)
- Reduce contention
- Maximize overlap of communication and processing (hide latency so as to not incur cost)
Reference
我都毕业半年多了居然还在看课件和视频orz 这毫无意义,不如刷题。但是人总是通过做一些不重要的事来避免做那些重要的事,通过做别的事来缓解不做该做的事的焦虑,所以我还在写,就如当时在晚上做鲜芋仙一样。反正也是自己的博客丧一丧没关系吧,头大脑壳痛。