Parallel Architecture & Programing 陆
就还觉得数据集就是个垃圾,根本不是imblance或者其他什么问题,学不出来的:) 一边train反正也train不出来的网络,一边学习Cache Coherence,我失忆,我不会。都是假的🤦♂️。每天工作都自闭啊啊啊啊啊啊啊我是一只土拨鼠了天哪我自闭到吃辣条,又吃了一个橙子。我自闭了。想了想可能还是要刷题,又回到学生时代那时候天天刷题,听小半,等我复习完PP我就不听了。
Snooping-Based Cache Coherence
Cache overview
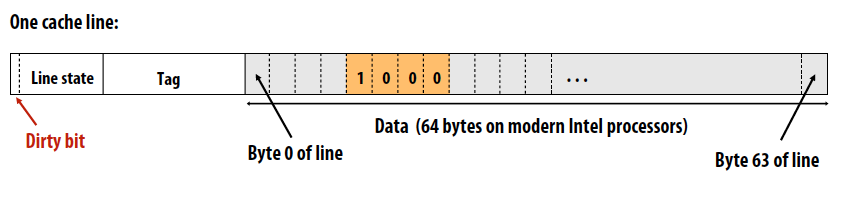
513的内容,一条长这样的cache line:
Writing policies
Write back vs. Write through cache
- Write-through: write is done synchronously both to the cache and to the backing store
- Write-back: writing is done only to the cache. The write to the backing store is postponed until the modified content is about to be replaced by another cache block
Allocate vs. Write-no-allocate cache
- Write allocate: data at the missed-write location is loaded to cache, followed by a write-hit operation. In this approach, write misses are similar to read misses.
- No-write allocate: data at the missed-write location is not loaded to cache, and is written directly to the backing store. In this approach, data is loaded into the cache on read misses only
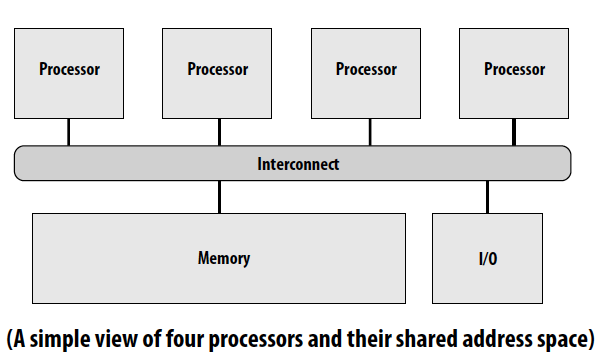
一个共享内存的多核处理器:
-
Processors issue load and store instructions
-
Reading a value at address X should return the last value written to address X by any processor
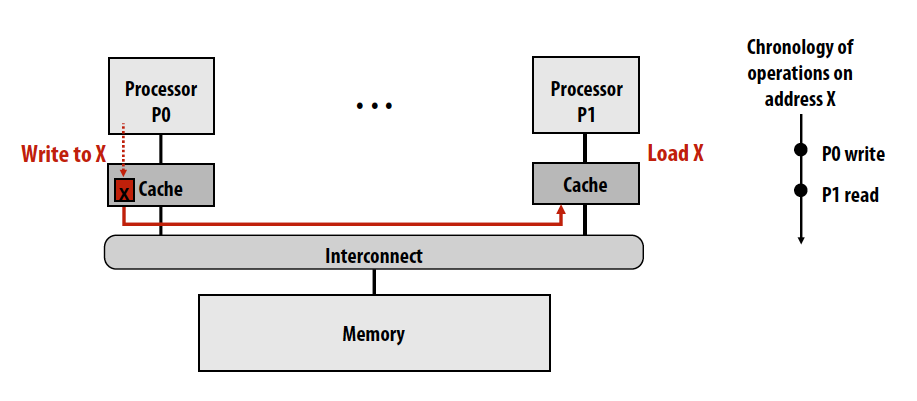
Cache coherence problem: processors can observe different values for the same memory location
Assume the initial value stored at address X is 0 and write-back cache behavior:
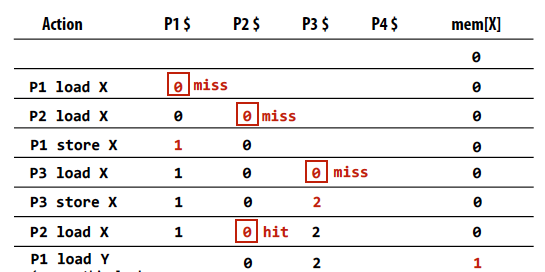
我也想不通当时为何一度看不懂这个图
- Memory coherence problem exists because there is both global storage (main memory) and per-processor local storage (processor caches) implementing the abstraction of a single shared address space
对于single CPU system:
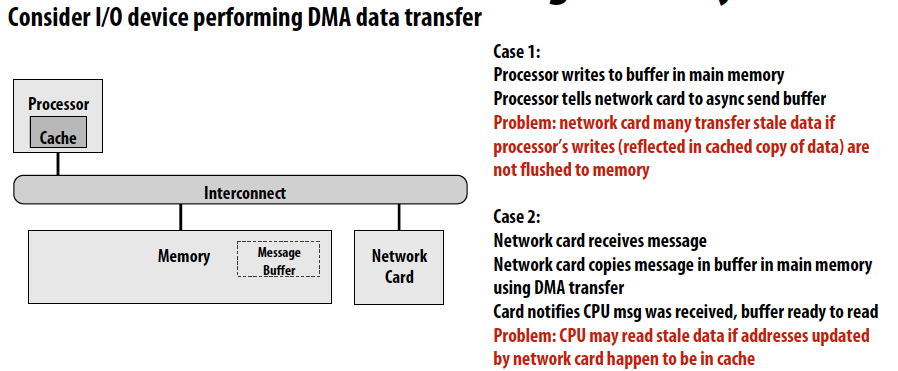
- Direct memory access(DMA)
- Common solutions:
- CPU writes to shared buffers using uncached stores
- OS support
Coherence
Definition :
-
Obeys program order: A read by processor P to address X that follows a write by P to address X, should return the value of the write by P (assuming no other processor wrote to X in between)
- Write propagation: A read by processor P1 to address X that follows a write by processor P2 to X returns the written value(assuming no other write to X occurs in between)
- Write serialization
- Writes to the same address are serialized: two writes to address X by any two processors are observed in the same order by all processors
Implementment:
- Software-based solutions
- Hardware-based solutions
- Snooping based coherence implementations 监听式缓存一致性
- Directory based coherence implementations 目录式缓存一致性
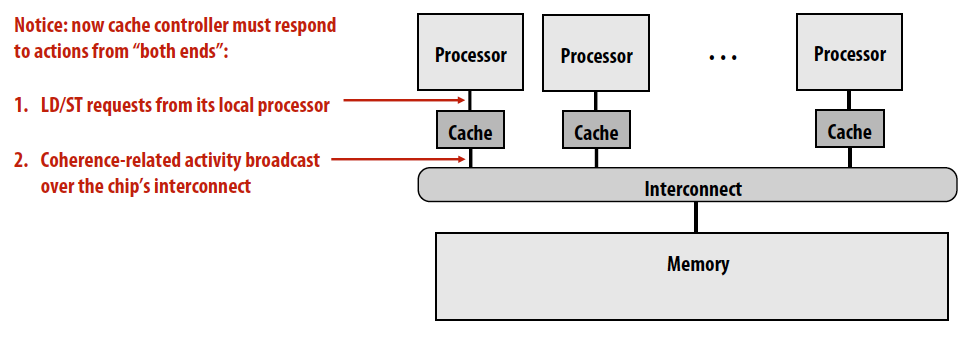
Snooping cache-coherence schemes
- Main idea: all coherence-related activity is broadcast to all processors
- Cache controllers monitor memory operations, and react accordingly to maintain memory coherence
对于Write-through caches:
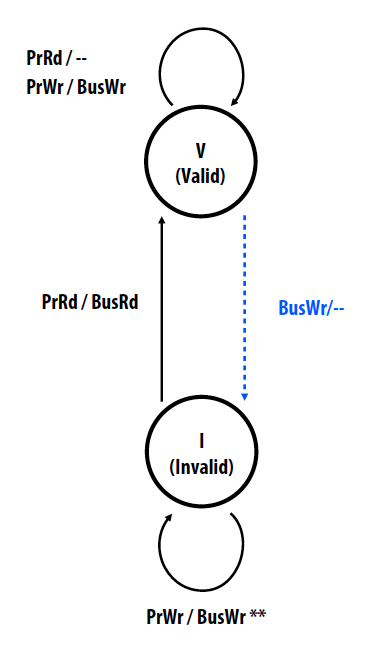
- Cache line states: Valid/Invalid
- Processor operations: Read/ Write (local processor)
-
Bus transactions: Bus read/Bus write (remote caches)
- Requirements of the interconnect:
- All write transactions visible to all cache controllers
- All write transactions visible to all cache controllers in the same order
这个状态图里cache line有两种状态,Invalid表示本地数据失效,需要从主存更新。每个cache controller控制本地读写操作,也能够知道其他cache controller控制的remote读写操作。Cache在Valid情况下本地读操作不会改变状态,写操作会引起Bus write通知其他controller改变cache line状态。Write-through的每一个写操作都会写入主存,具有很高的带宽要求,因此是低效的。
对于Write-back caches:
- Exclusive: cache is only cache with a valid copy of line
- Owner: cache is responsible for supplying the line to other processors when they attempt to load it from memory
Invalidation-based write back
Key ideas:
- A line in the “exclusive” state can be modified without notifying the other caches
- Processor can only write to lines in the exclusive state
- When cache controller snoops a request for exclusive access to line it contains it must invalidate the line in its own cache
MSI invalidation protocol
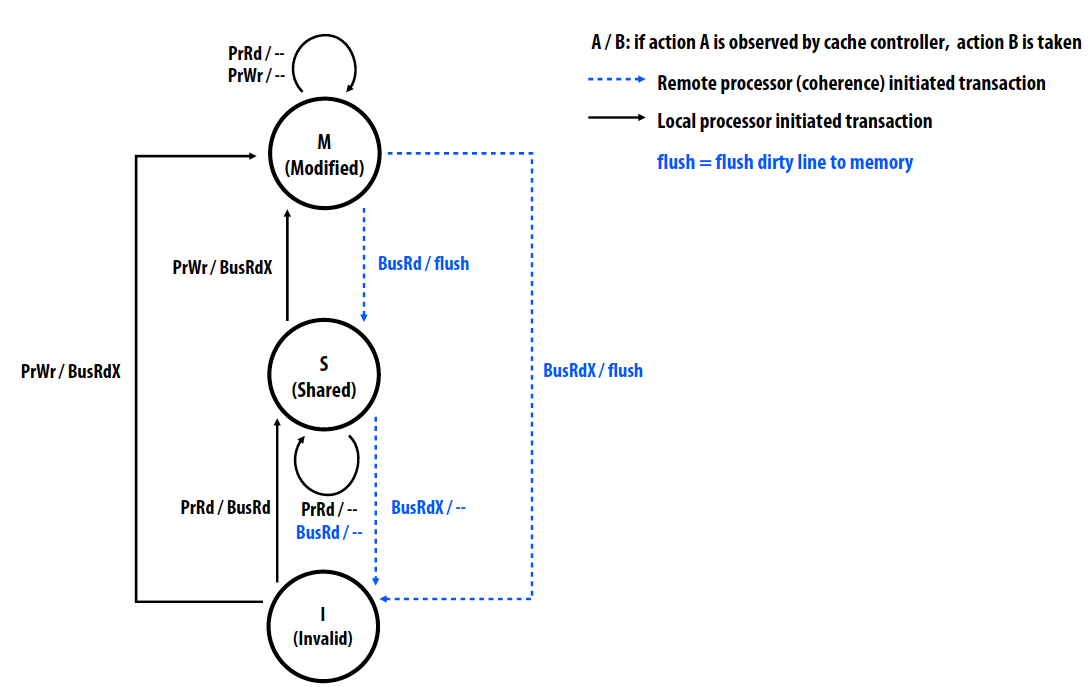
- Cache line states:
- Invalid(I)
- Shared(S): line valid in one or more caches
- Modified(M): line valid in exactly one cache (dirty/exclusive)
- Processor operations: Read/Write
- Bus transactions:
- BusRd: obtain copy of line with no intent to modify
- BusRdX: obtain copy of line with intent to modify
- flush: write dirty line out to memory
当Cache line的状态为M时,local processor可以更改这条cache line而不用通知其他cache。当cache的状态不是M时,processor不可以写入这一条cache,而是通过bus read-exclusive将cache的状态改为M,并告知其他cache即将更改。当cache controller检测到remote read-exclusive操作,这一条cache line的状态会变成Invalid。通过bus read和bus read-exclusive,MSI可以满足write propagation和write serialization。
MSEI invalidation protocol
MSEI protocol通过加入E这一状态来减少MSI protocal中interconnect transactions的低效问题。
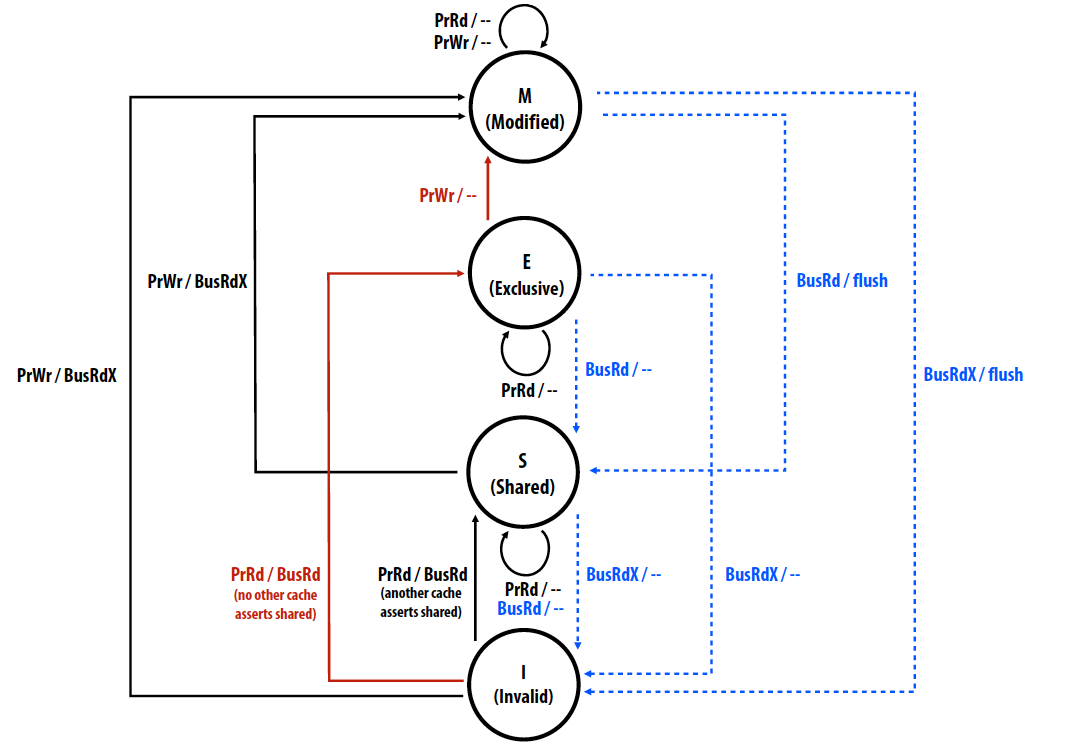
E: “exclusive clean” 独占且与主存一致
- Line has not been modified, but only this cache has a copy of the line
- Decouples exclusivity from line ownership
- Upgrade from E to M does not require an interconnect transaction
Cache状态由E到M无需总线读写,节省了带宽。更多的状态能够提升效率,同时也提高了复杂度,比如MESIF和MOESI.
Update-based protocols
对于Invalidation-based protocol, cache必须独占一条cache line才可以写入,其他cache需要invalidate copies. 对于Update-based protocol,cache可以通过广播更新所有copies来写入。
Dragon write-back update protocol
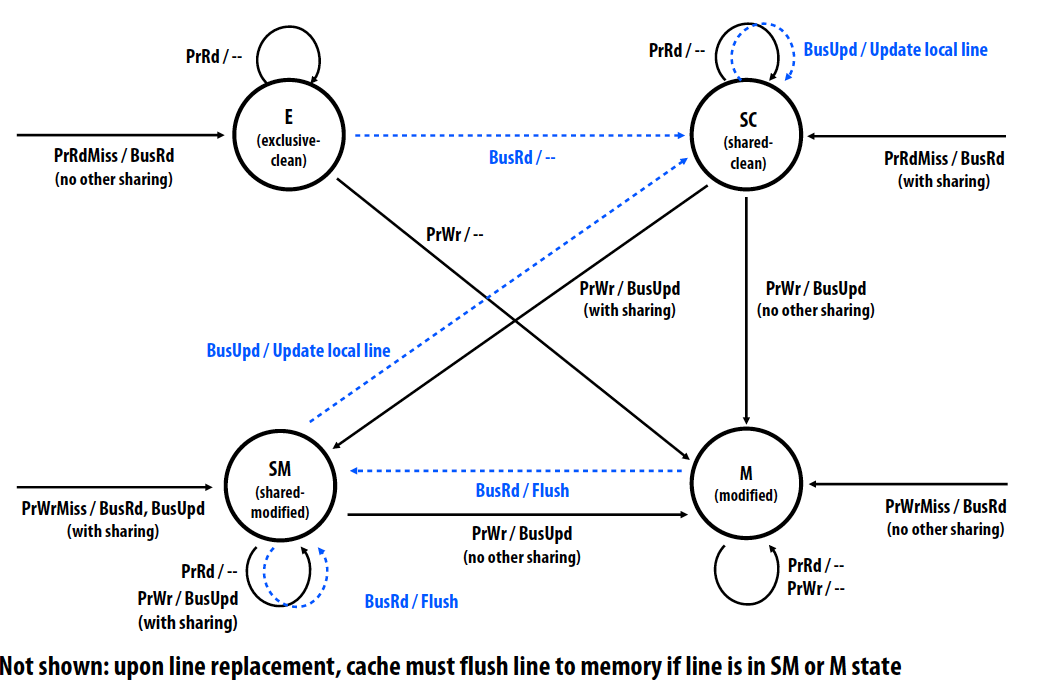
- Cache states:
- Exclusive clean(E): only one cache has line, memory up-to-date
- Shared-clean(SC): multiple caches may have line, and memory may or may not be up to date
- Shared-modified(SM): multiple caches may have line, memory not up to date
- Only one cache can be in this state for a given line (but others can be in SC)
- Cache with line in SM state is “owner” of data. Must update memory upon eviction
- Modified(M): only one cache has line, it is dirty, memory is not up to date
- Cache is owner of data. Must update memory upon replacement
- Processor actions: Read/Write/ReadMiss/WriteMiss
- Bus transactions:
- Bus read
- flush: provide entire line to others
- Bus update: provide partial line to others
- Overhead if:
- Data just sits in caches
- Application performs many writes before the next read
Summary
- The cache coherence problem exists because the abstraction of a single shared address space is not implemented by a single storage unit
- Main idea of snooping-based cache coherence: whenever a cache operation occurs that could affect coherence, the cache controller broadcasts a notification to all other cache controllers
- Challenge for HW architects: minimizing overhead of coherence implementation
- Challenge for SW developers: be wary of artifactual communication due to coherence protocol (e.g., false sharing)
- Scalability of snooping implementations is limited by ability to broadcast coherence messages to all caches
False Sharing
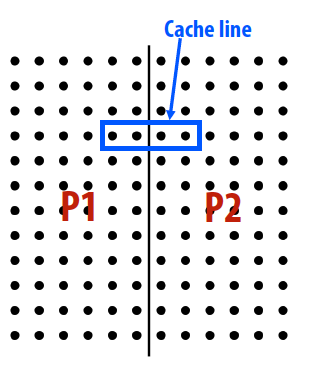
- Condition where two processors write to different addresses, but addresses map to the same cache line
- Cache line “ping-pongs” between caches of writing processors, generating significant amounts of communication due to the coherence protocol
- No inherent communication, this is entirely artifactual communication

伪共享发生在多个processor修改同一cache line的数据,为了保证cache coherence,这条cache line的状态不断改变,需要通过主存中读写来更新。
Directory-Based Cache Coherence
监听式通过广播一致性消息来决定其他cache中cache line的状态。将cache line的状态存储在目录中可以减少总线的使用。
一个分布式的目录:
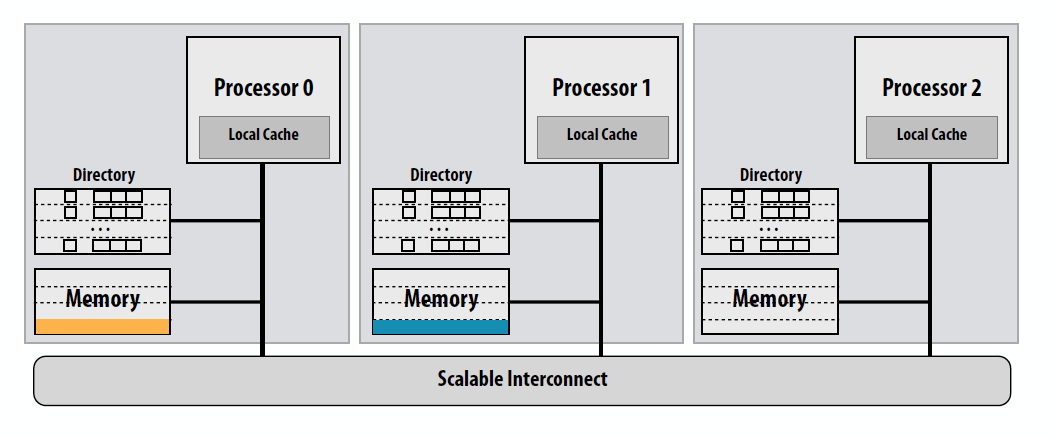
- Home node: node with memory holding the corresponding data for the line
- Requesting node: node containing processor requesting line
- Ring-based schemes can be much simpler than point-to-point communication
Read miss的情况:
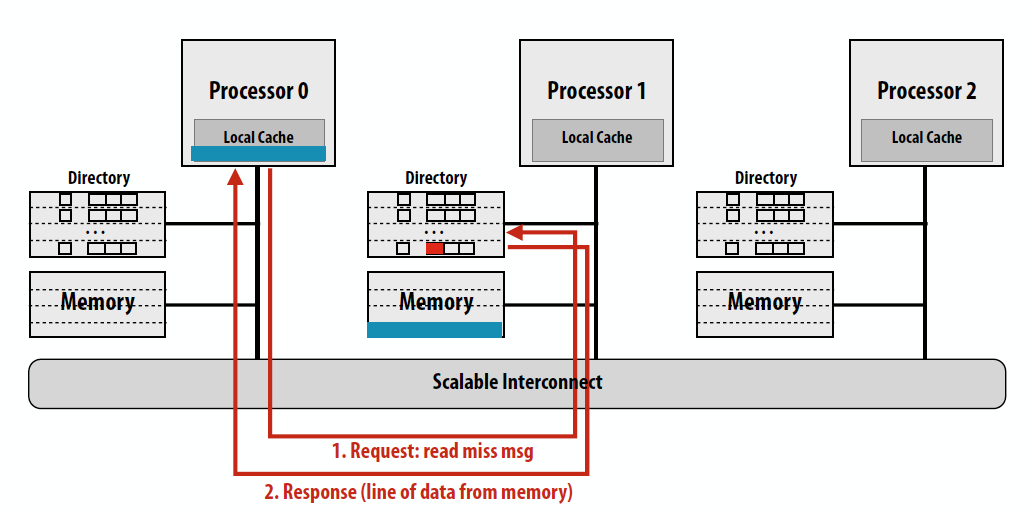
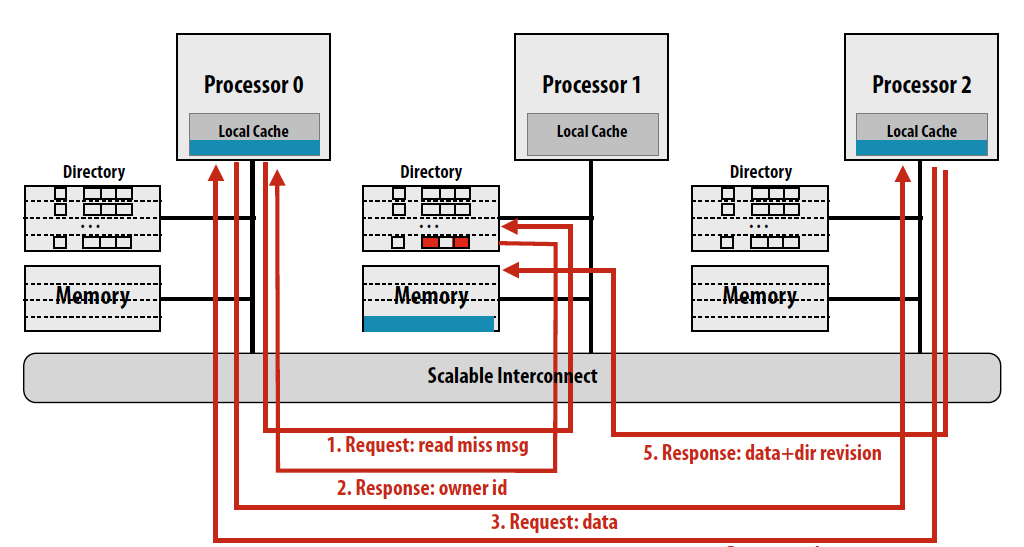
简而言之,对于读操作home node的directory中存着cache line的信息,如果clean就返回内容并且更新目录,如果dirty就返回最新的cache line所存在的node,这个node收到request后会返回cache line的内容给request node和home node,cache line在home中的状态变为clean。
Write miss的情况同理:
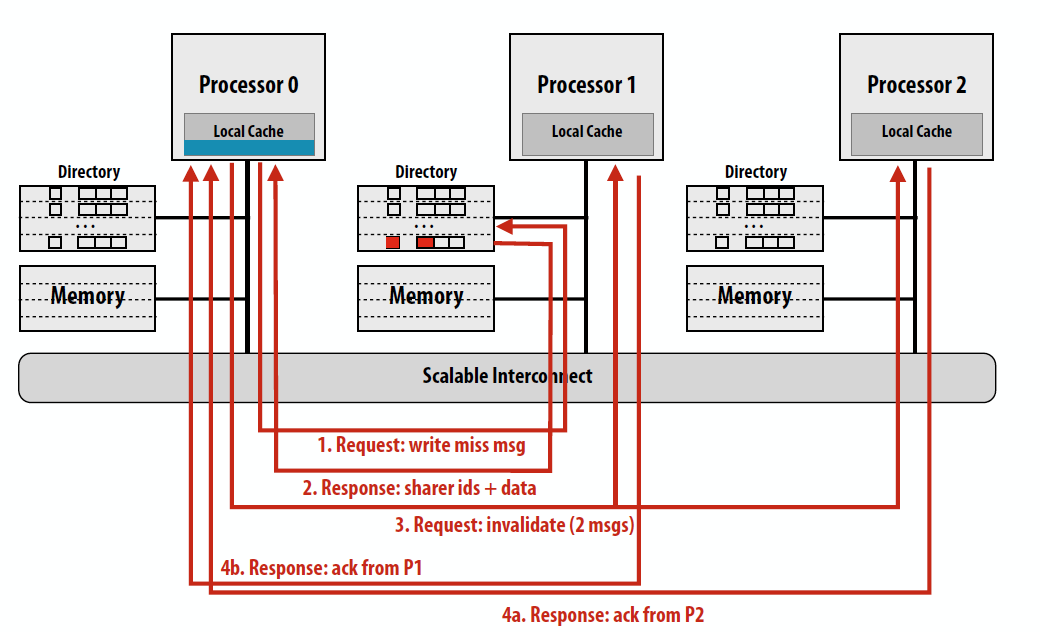
Advantage of directories:
- On reads, directory tells requesting node exactly where to get the line from
- On writes, the advantage of directories depends on the number of sharers
- If all caches are sharing data, all caches must be communicated with
- Directories are useful for limiting coherence traffic
Challenge: reducing overhead of directory storage
- Use hierarchies of processors or larger line sizes
- Limited pointer schemes: exploit fact the most processors not sharing line
- Sparse directory schemes: exploit fact that most lines are not in cache
Deadlock & Livelock & Starvation
Deadlock 死锁
A system has outstanding operations to complete, but no operation can make progress.
Required conditions:
- Mutual exclusion: one processor can hold a given resource at once
- Hold and wait: processor must hold the resource while waiting for other resources needed to complete an operation
- No preemption: processors don’t give up resources until operation they wish to perform is complete
- Circular wait: waiting processors have mutual dependencies
Livelock 活锁
A system is executing many operations, but no thread is making meaningful progress.
Starvation 饥饿
A system is making overall progress, but some processes make no progress. Starvation is usually not a permanent state.
就这样吧,今天不是很有好好学习这个东西的兴致。最后用一张ppt收尾,就这样吧。

Reference
Avoiding and Identifying False Sharing Among Threads