Parallel Architecture & Programing VIII
🍋🍋🍋包围着我,今天也要加油鸭。WFH了所以没有自闭,甚至没有工作,而是在学习如何实现同步,虽然没啥用。啊啊啊啊啊啊啊内心十分难受了。啊难受_(:з」∠)_我是想好好工作的
Implemenging Locks
Primitives for ensuring mutual exclusion
- Locks
- Atomic primitives
- Transactions
Primitives for event signaling
- Barriers
- Flags
Three phases of a synchronization event
- Acquire method
- Waiting algorithm
- Busy waiting (spinning)
- Scheduling overhead is larger than expected wait time
- Processor’s resources not needed for other tasks
- Blocking: if progress cannot be made because a resource cannot be acquired, it is desirable to free up execution resources for another thread
- Busy waiting (spinning)
- Release method
Desirable lock performance
-
Low latency: If lock is free and no other processors are trying to acquire it, a processor should
be able to acquire the lock quickly
- Low interconnect traffic: If all processors are trying to acquire lock at once, they should acquire the lock in succession with as little traffic as possible
- Scalability: Latency / traffic should scale reasonably with number of processors
- Low storage cost
- Fairness: Avoid starvation or substantial unfairness
Test and set lock
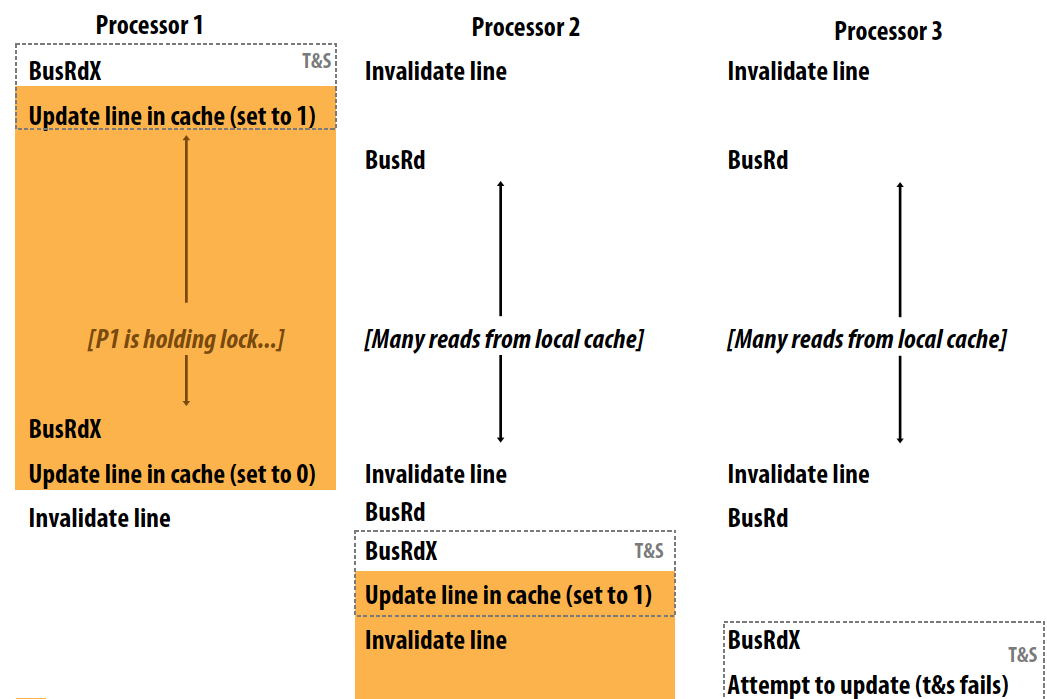

Characteristics:
- Slightly higher latency than test-and-set in uncontended case
- Generates much less interconnect traffic
- One invalidation, per waiting processor, per lock release (O(P) invalidations)
- O(P2) interconnect traffic if all processors have the lock cached
- Test-and-set lock generated one invalidation per waiting processor per test
- More scalable (due to less traffic)
- Storage cost unchanged (one int)
- Still no provisions for fairness
Test-and-set lock with back off:
- Upon failure to acquire lock, delay for awhile before retrying
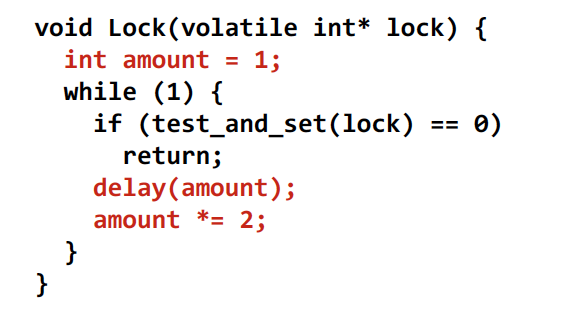
- Same uncontended latency as test-and-set, but potentially higher latency under contention
- Generates less traffic than test-and-set
- Improves scalability (due to less traffic)
- Storage cost unchanged
- Exponential back-off can cause severe unfairness (newer requesters back off for shorter intervals)
- Main problem with test-and-set style locks: upon release, all waiting processors attempt to acquire lock using test-and-set
想回工大吃年夜饭 Test and set lock保证共享资源在任一时刻只有一个锁的拥有者,其他处理器busy waiting.
Ticket lock
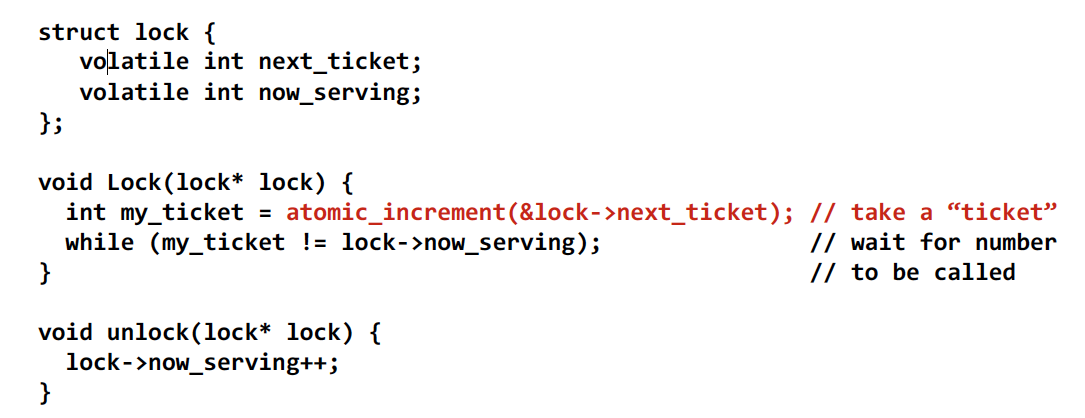
- No atomic operation needed to acquire the lock (only a read)
- Only one invalidation per lock release (O(P) interconnect traffic)
Array-based lock

- Each processor spins on a different memory address
-
Utilizes atomic operation to assign address on attempt to acquire
- O(1) interconnect traffic per release, but lock requires space linear in P
- The atomic circular increment is a more complex operation (higher overhead)
Queue-based Lock (MCS lock)
- Create a queue of waiters
- Each thread allocates a local space on which to wait
- Pseudo-code:
- Glock – global lock
- Mlock –my lock (state, next pointer)

Implementing Barriers
Centralized barrier


- O(P) traffic on interconnect per barrier:
- All threads: 2P write transactions to obtain barrier lock and update counter
- Last thread: 2 write transactions to write to the flag and reset the counter
- Still serialization on a single shared lock
- So span (latency) of entire operation is O(P)
- Optimization:Tree implementation
Tree implementation of barrier
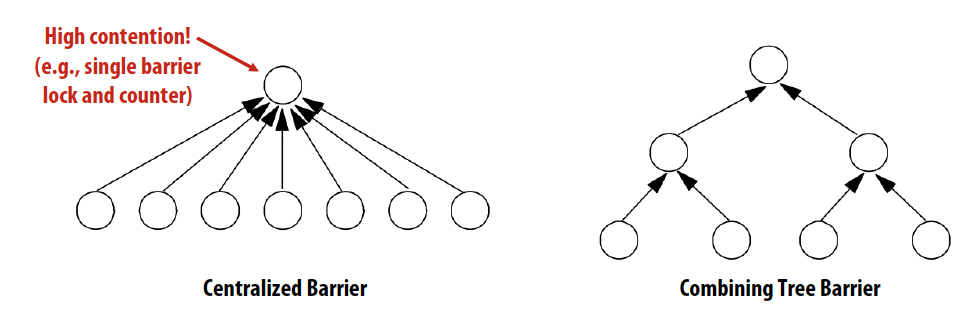
- Combining trees make better use of parallelism in interconnect topologies
- lg(P) span (latency)
- Strategy makes less sense on a bus (all traffic still serialized on single shared bus)
- Barrier acquire: when processor arrives at barrier, performs increment of parent counter
- Barrier release: beginning from root, notify children of release
Fine-grained locking
- Use fine-grained locking to reduce contention (maximize parallelism) in operations on shared data structures
- But fine-granularity can increase code complexity (errors) and increase execution overhead
细粒度同步,举个向有序链表中插入节点的例子:
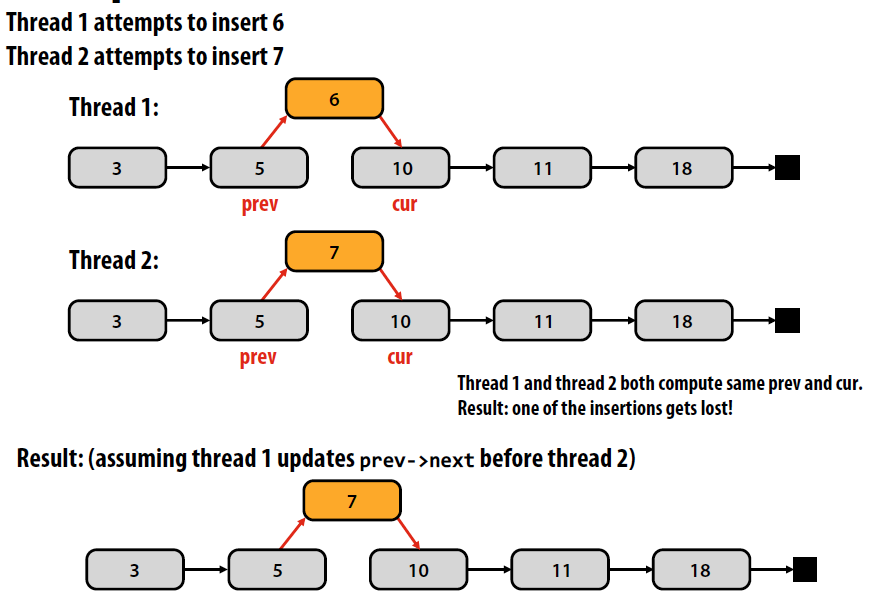
多个线程同时修改导致丢失节点。
Solution 1: protect the list with a single lock

- Good: Simple
- Bad: Operations on the data structure are serialized
Solution 2: fine-grained locking

- Goal: enable parallelism in data structure operations
- Reduces contention for global data structure lock
- In linked-list example: a single monolithic lock is overly conservative
- Challenge: tricky to ensure correctness
- Costs
- Overhead of taking a lock each traversal step
- Extra storage cost
每个node都拥有自己的锁,或许前后两个相邻节点的锁后可以插入新节点。
Lock-free data structures
-
An algorithm that uses locks is blocking regardless of whether the lock implementation uses spinning or pre-emption
- Non-blocking algorithms are lock-free if some thread is guaranteed to make progress (“systemwide progress”)
- Lock-free data structures: non-blocking solution to avoid overheads due to locks
- But can be tricky to implement
- Still requires appropriate memory fences on modern relaxed consistency hardware
- A lock-free design does not eliminate contention
Single reader, single writer unbounded queue:

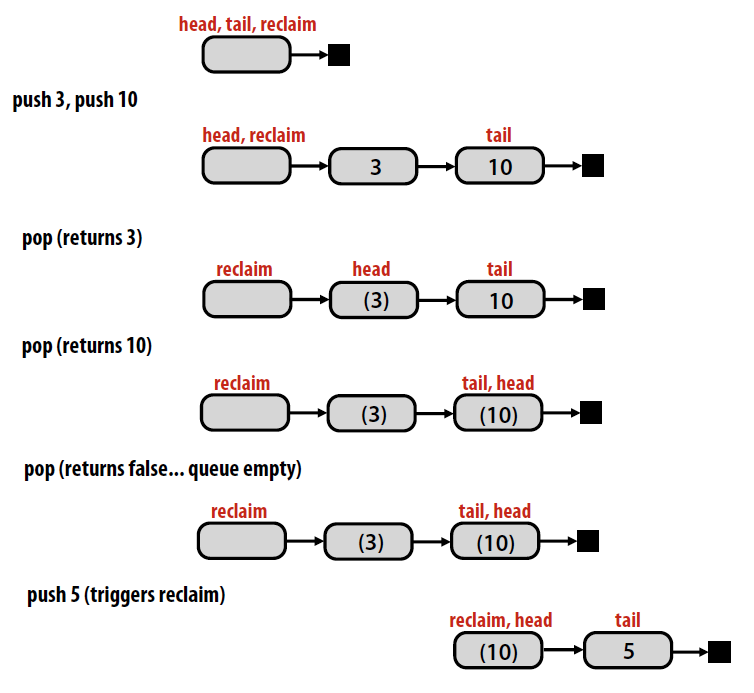
- Tail points to last element added
- Head points to element BEFORE head of queue
- Allocation and deletion performed by the same thread
- Only push modifies tail & reclaim; only pop modifies head
ABA problem
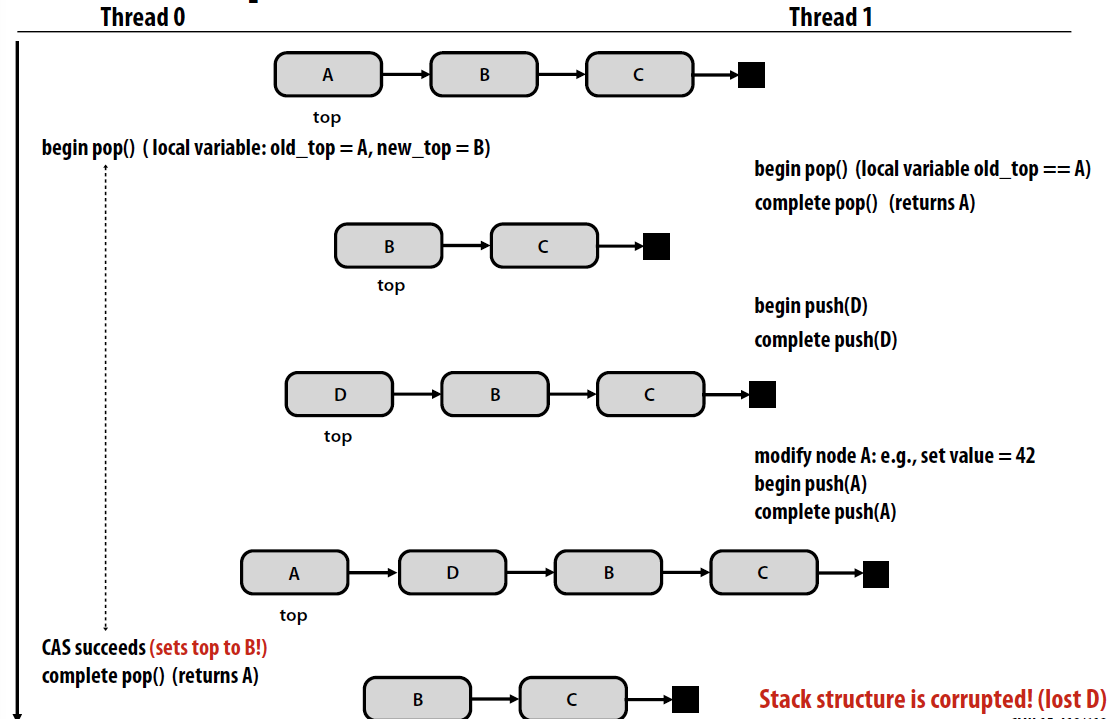
ABA问题,compare and swap中可能导致的一个问题,也可以通过版本戳解决。

- Maintain counter of pop operations
- Requires machine to support “double compare and swap” (DCAS) or doubleword CAS
- Could also solve ABA problem with node allocation and/or element reuse policies
Another ABA solution: Hazard Pointers

- Node cannot be recycled or reused if matches any hazard pointer
Reference
Lock-Free Code: A False Sense of Security
Common Pitfalls in Writing Lock-Free Algorithms