Parallel Architecture & Programing X
下雪啦\(//∇//)\!!!❄️❄️❄️感觉后面的几节没什么特别复习的必要,看看知道有这么个东西就可以了~不过为了凑个整于是出现了X篇。过完年好好刷题。


Message passing model
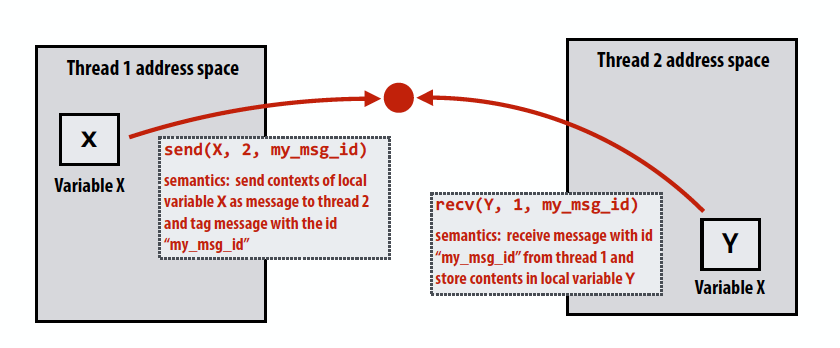
- Threads operate within their own private address spaces
- Threads communicate by sending/receiving messages
- send: specifies recipient, buffer to be transmitted, and optional message identifier
- receive: sender, specifies buffer to store data, and optional message identifier
- Sending messages is the only way to exchange data between threads 1 and 2
- Popular software library: MPI (message passing interface)
- Hardware need not implement system-wide loads and stores to execute message passing programs
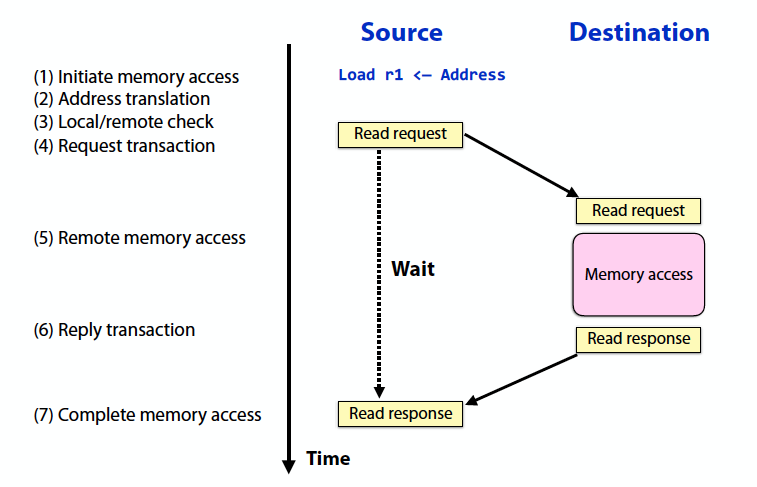
Network Transaction
![]()
- One-way transfer of information from a source output buffer to a destination input buffer
- causes some action at the destination
- occurrence is not directly visible at source
Shared Address Space Abstraction
- Fundamentally a two-way request/response protocol
- writes have an acknowledgement
- Source and destination addresses are specified by source of the request
- a degree of logical coupling and trust
- No storage logically “outside the application address space(s)”
- may employ temporary buffers for transport
- Operations are fundamentally request-response
- Remote operation can be performed on remote memory
Message Passing Implementation Options
-
Synchronous
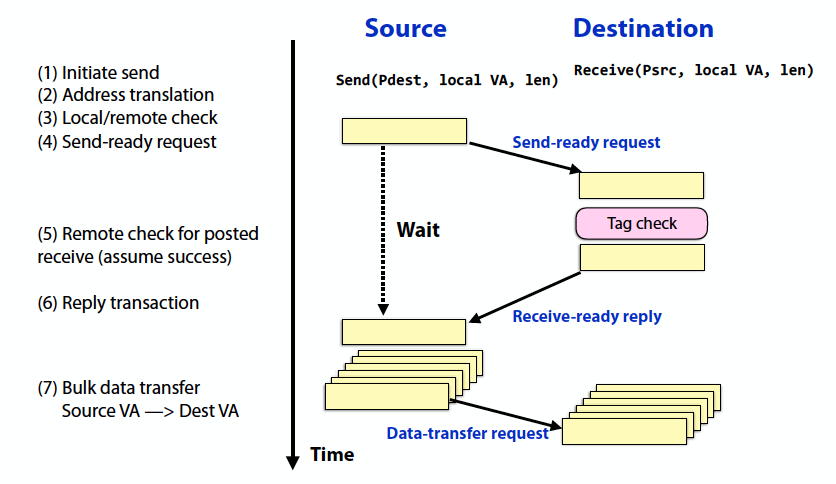
- Send completes after matching receive and source data sent
- Receive completes after data transfer complete from matching send
- Data is not transferred until target address is known
- Limits contention and buffering at the destination
-
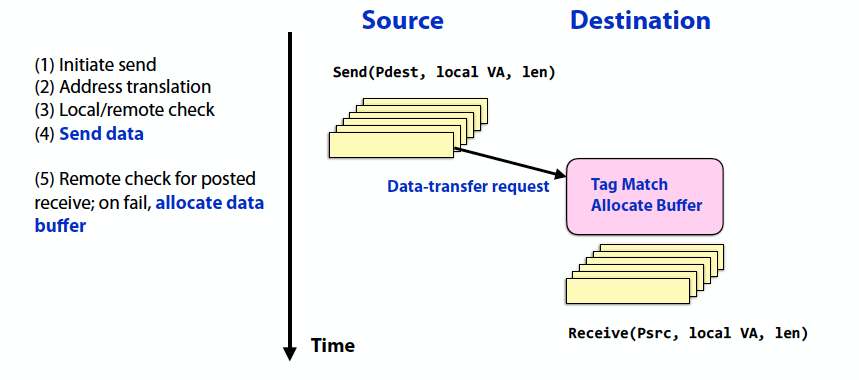
Asynchronous
-
Send completes after send buffer may be reused
-
Good: source does not stall waiting for the destination to receive
-
Bad: storage is required within the message layer
-
-
Key Features of Message Passing Abstraction
- Source knows send address, destination knows receive address (after handshake)
- Arbitrary storage “outside the local address spaces”
- may post many sends before any receives
- Fundamentally a 3-phase transaction
- includes a request / response
- can use optimistic 1-phase in limited “safe” cases
Challenge
Avoiding Input Buffer Overflow
- Requires flow-control on the sources
- Approaches:
- Reserve space per source
- Refuse input when full
- Drop packets
Avoiding Fetch Deadlock
- Must continue accepting messages, even when cannot source msgs
- Approaches:
- Logically independent request/reply networks
- Bound requests and reserve input buffer space
- NACK on input buffer full
Big Picture
- One-way transfer of information
- No global knowledge, nor global control
- Very large number of concurrent transactions
- Management of input buffer resources
- Latency is large enough that you are tempted to “take risks”
Reference
就这样叭~

随便完结,甚至毫无好好学习天天向上还想吃小龙虾_(:з」∠)_
